隨著企業數據量的爆炸式增長和數據源的日益多樣化,傳統的數據管理與集成方式已難以滿足現代業務對實時性、靈活性和安全性的需求。在此背景下,“數據編織”作為一種創新的數據管理和集成架構,正迅速成為企業構建智能化數據處理與存儲支持服務的核心框架。
一、數據編織的定義與核心理念
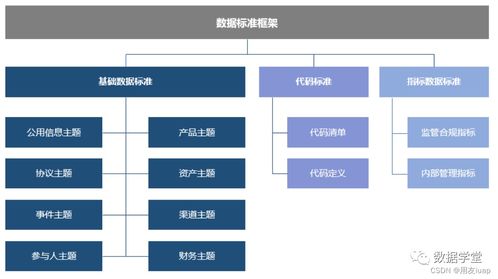
數據編織是一種集成的數據架構,它通過結合元數據、知識圖譜、人工智能和自動化技術,為跨平臺、跨環境的數據提供統一的訪問、集成、管理和治理能力。其核心理念在于構建一個智能的、自適應的“數據網絡”,使得數據能夠像織物一樣被靈活地編織在一起,無論數據存儲在何處、格式如何,都能被高效地發現、理解和使用。
與傳統的點對點集成或數據湖/倉庫模式不同,數據編織強調以業務為中心,通過主動元數據驅動,實現數據的上下文感知和智能推薦,從而降低數據管理的復雜性,提升數據利用效率。
二、數據編織如何支持數據處理與存儲服務
1. 統一的數據訪問與集成層
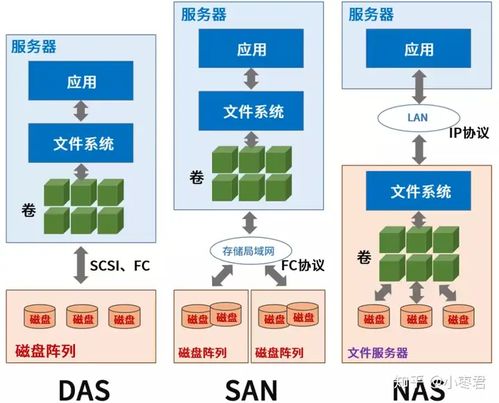
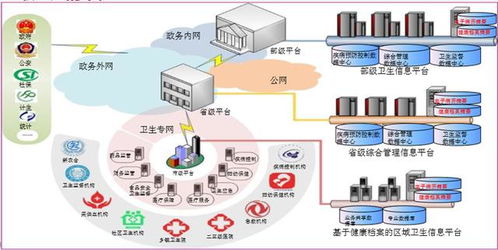
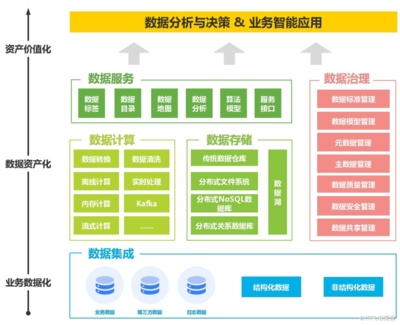
數據編織在底層異構的數據存儲(如關系數據庫、數據湖、云存儲、邊緣設備等)之上構建了一個抽象層。通過連接器、API和標準化協議,它能夠無縫集成結構化、半結構化和非結構化數據,為用戶和應用提供統一的查詢接口,無需關心數據的具體位置和格式。
2. 智能的元數據驅動管理
數據編織的核心是主動元數據。它不僅被動地描述數據(如模式、位置),還通過持續收集數據使用情況、血緣關系、業務術語、數據質量指標等信息,形成豐富的上下文。結合AI/ML技術,系統可以自動推薦相關數據集、檢測數據異常、優化查詢性能,甚至預測存儲需求,實現數據管理的自動化與智能化。
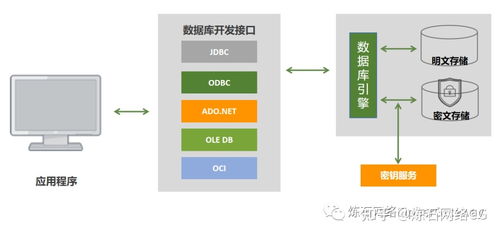
3. 增強的數據治理與安全
通過全局的數據血緣和策略引擎,數據編織能夠實施一致的數據治理策略(如隱私合規、訪問控制、生命周期管理)。無論數據在何處移動或處理,策略都能自動附著和執行,確保數據安全與合規,同時提供透明的審計跟蹤。
4. 靈活、可擴展的架構支持
數據編織采用分布式、微服務化的架構,支持混合云和多云環境。這使得數據處理和存儲服務可以根據業務需求動態擴展,實現成本優化和性能提升。例如,熱數據可以存放在高性能存儲中,而冷數據自動歸檔到成本更低的存儲層。
三、數據編織的關鍵技術組件
- 知識圖譜:將元數據、業務術語和數據資產之間的關系以圖的形式建模,提供強大的語義搜索和關聯發現能力。
- AI與機器學習:用于元數據豐富、自動化分類、異常檢測、優化建議等。
- 數據虛擬化:實現數據的邏輯整合,避免不必要的數據移動和復制。
- 自動化編排與運維:自動化執行數據集成、質量檢查、策略實施等任務。
四、應用價值與未來展望
數據編織為企業帶來的核心價值在于:
- 提升數據發現與使用效率:業務用戶能更快地找到可信數據,加速分析洞察。
- 降低集成與管理成本:減少手動編碼和重復工作,簡化數據架構。
- 增強業務敏捷性:快速響應新的數據需求,支持創新應用。
- 保障數據可信與合規:建立端到端的可觀測性與控制力。
隨著企業數字化轉型的深入,數據編織正從概念走向落地。它不僅是技術架構的演進,更是向以數據為中心、智能驅動的運營模式的轉變。結合邊緣計算、實時流處理等趨勢,數據編織有望成為企業數據基礎設施的“中樞神經系統”,為無處不在的數據處理與存儲需求提供無縫、智能的支持服務。
###
總而言之,數據編織代表了數據管理范式的一次重要飛躍。它通過智能、自適應的方式連接分散的數據孤島,為企業構建了一個靈活、可靠且高效的數據支持層。對于任何希望充分釋放數據潛力、驅動數字化轉型的組織而言,理解和投資數據編織架構,將是構建未來競爭力的關鍵一步。